

区块链开发公司交易量排名的加密货币交易所- 加密货币所谈开发知识第五篇
2026-04-13交易所,交易所排名,交易所排行,加密货币是什么,加密货币交易平台,加密货币平台,币安交易所,火币交易所,欧意交易所,Bybit,Coinbase,Bitget,Kraken,全球交易所排名,交易所排行(本文有彭利编写,有需求联系本人请看文章结尾)我前面讲到了一些开发方面的一些大体需要的一些方法知识和技巧,开发这个货币交易所涉及的开发语言也很多,需要的注意的也很多,下面的文章我将会按照顺序来讲,今天先说一下 PKI 体系.闪电网络.共识机制.管理账户信息的代码包accounts.Manager订阅Wallet的更新事件. 软件实现的Wallet - keystore.
本地文件显式存储账户信息.以本地加密文件存储公钥密钥.硬件设备实现的Wallet.Ethereum服务.
以太坊客户端程序.待挖掘区块需要组装.新区块的组装流程.算法.这些方面,话不多说看下面的文章交易要经过的记账流程是这样的大家看图片
在以太坊源代码的accounts代码包中,呈现账户地址的最小结构体叫Account{},它的主要成员就是一个common.Address类型变量;管理Account的接口类叫Wallet,类如其名,声明了诸如缓存Account对象及解析Account对象等操作,管理多个对象的结构体叫Manager,这些类型的UML关系如下图所示:
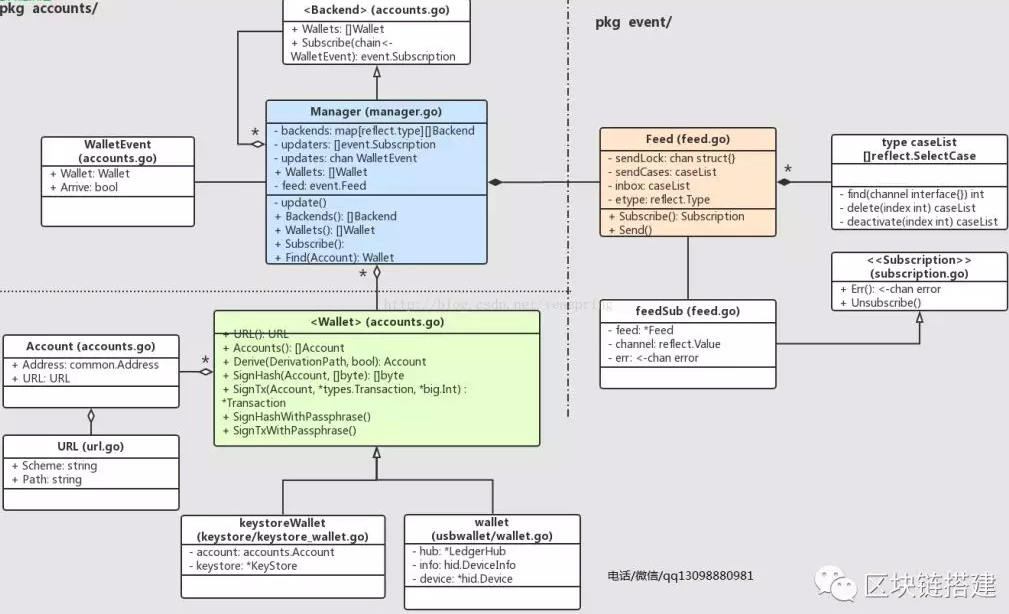
在accounts代码包内部的各种结构体/接口中,accounts.Manager在相互调用关系上无疑是处于顶端的,它本身是公共类,向外暴露包括查询单个Account,返回单个或多个Wallet对象,订阅Wallet更新事件等方法。在其内部它维持一个Wallet列表,通过每个Wallet实现类持有一组Account账户对象,并通过一个event.Feed成员变量来管理所有向它订阅Wallet更新事件的需求。
首先注意这个Subscribe()函数是让外部调用对象 向该Manager作订阅的操作,事实上该Manager本身也是通过相同的订阅机制去获知新添的Wallet对象,它的成员变量updates就是该Manager本身得到所订阅事件的通道。其次,Manager.Subscribe()函数只有一个chan参数,由于golang语言中channel机制的强大,订阅操作仅仅需要一个chan对象就足够了,真是简单之极,根本不必知道背后是谁发起了订阅。尽管如此,这里依然值得思考的是,究竟是什么对象向Manager发起了订阅呢?其实,向某个Manager对象订阅Wallet更新事件的,正是另外一个Manager对象,也就是的实现类。
得出以上这个结论,是很有意义的。后面可以了解到,accounts.Manager主要作为eth.Ethereum(或者les.Ethereum)的一个成员存在,而这个eth.Ethereum是以太坊客户端程序中最主要的部分,它以服务的形式提供几乎所有以太坊系统运行所需的功能,所以一个以太坊客户端可视为一个accounts.Manager的存在,那么真相就是,所有以太坊客户端之间在通过accouts.Manager相互订阅Wallet更新事件。
·event.Feed{}:它可以管理一对多的订阅模式,每个调用者提供一个chan对象,用以发送所订阅的内容。Feed{}处理的订阅内容是类型泛化的,而每一个Feed{}对象,在其生命周期内,只能处理一种类型的订阅内容,即向chan对象发送的value。Feed.Subscribe()方法返回接口的实现体feedSub{},Feed.Subscribe()帮助Manager实现了所声明的方法Subscribe()。在Feed结构体内部,CaseList被用来管理所有订阅者发过来的chan对象。
·accounts.Account{}:它的成员除了一个common.Address类型,即20bytes长的地址变量外,还有一个可选成员URL,可以是网址,也可以是本地存储的路径+文件全名。在以网址形式存在时,URL.Scheme就是网络协议名,而作为本地存储文件时,URL.Scheme是字符串常量keystore。
·accounts.:它很像一般意义上的“钱包”,其管理的多个Account,恰似个人用户在现实中拥有的多个银行账户,每个Account上的Ether余额,可从数据库(core.state.StateDB)中查询。接口声明的函数中,尤其需要注意的是SignXXX(),其中SignTx()是对一个Transaction(tx)对象进行数字签名,SignHash()是对一个Hash值进行数字签名,由于任何一个对象(只要可序列化)可以作Hash运算,所以这里SignHash()其实是针对任何一个对象,尤其是Block区块作数字签名。
是接口类型,它的实现体包括软件钱包(keystore.keystoreWallet)和硬件钱包(usbwallet.wallet),注意这里的硬件钱包是有实物的。之下的代码体系对于外部都不是公共的,所有向外暴露的“钱包”对象以及相关更新事件,都是以形式存在。
软件实现Wallet主要通过本地存储文件的方式来管理账户地址。同时,对象需要对交易或区块对象提供数字签名,这需要用到椭圆曲线数字签名(ECDSA)中的公钥+密钥,而每个公钥也是某个账户地址(Address)的来源,所以我们也需要本地存储ECDSA的公钥密钥信息。以太坊中这个通过本地存储文件的方案实现accounts.功能的机制被成为keystore。
的软件钱包实现的相关代码都处于/accounts/keystore/路径下,这组代码的主要UML关系如下图:
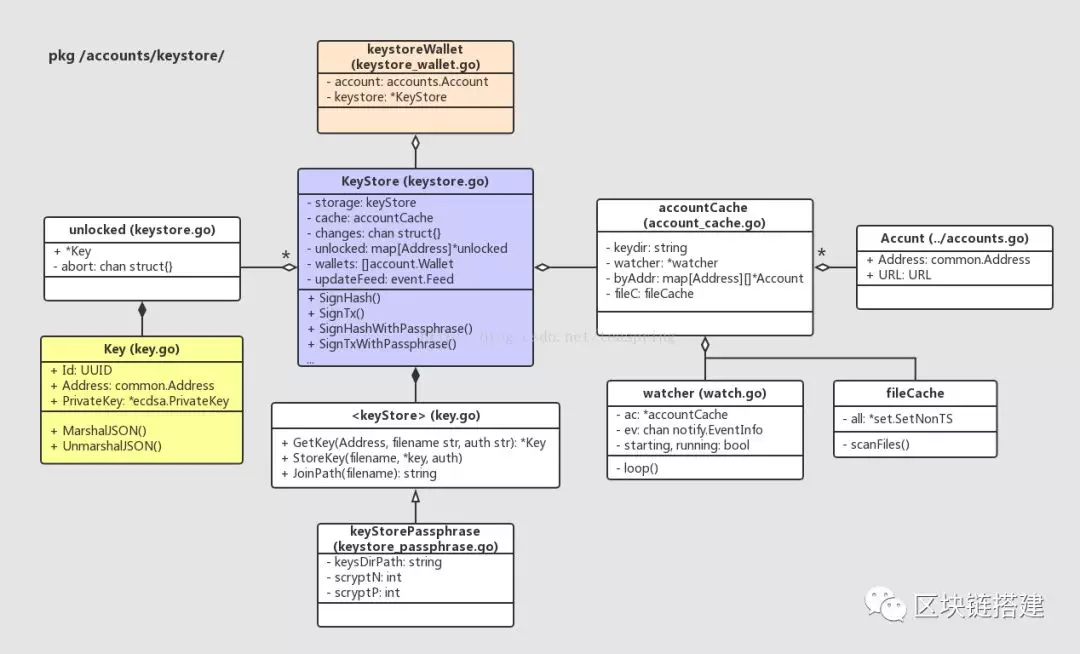
另外,KeyStore{}中有一个接口类型的成员storage,用来对存储在本地文件中的公钥信息Key做操作。
Unlocked{}:公钥密钥数据类Key{}的封装类,其内部成员除了Key{}之外,还提供了一个chan类型变量abort,它会在KeyStore对于公钥密钥信息的管理机制中发挥作用。
Key{}:存放数字签名公钥密钥的数据类,其内部显式存储了一个ecdsa.PrivateKey{}类型的成员变量,前文介绍过,Golang原生代码包中的ecdsa.PrivateKey{}中含有PublicKey{}类型的成员。而Key{}中同时携带Address类型成员变量,也可以避免公钥向地址类型转化的操作重复发生。
:这个接口类型声明了操作Key的函数,注意它与KeyStore{}在名字上仅有一个字母大小写的差异。
fileCache{}:keystore中可观察到的文件的缓存,它可对某个路径下存放的文件进行扫描,分别返回新增文件,缺失文件,改动文件的集合。
watcher{}:用来监测某个路径中存储的账户文件的变化,可以定时调用accountCache的方法对文件进行扫描。
accountCache缓存的帐号信息,均来自于某个已知路径下存储的本地文件集合。每个文件都是JSON格式,以显式存放Address: {Address: @Address},所以accountCache在读取文件后,可以直接转化成Account{}对象,在代码中使用。这里以显式文件存储Address信息没有任何问题,既不用担心Address信息泄露造成危害(无法从Address反向解析出源头的ECDSA所用公钥),又可以方便代码调用。
在使用中,watcher对象会维护一个定时器,不断的通知accountCache扫描某个给定的路径;accountCache会调用fileCache对象去扫描该路径下的文件,并根据fileCache返回的三种文件集合:新添文件、缺失文件、改动文件,在自身维护的Account集合中作相应操作。
Key{}通过ecdsa.PrivateKey对象从而同时携带ECDSA所用的公钥密钥,所以这里涉及到公钥密钥部分,都是针对Key对象做的操作。keystore机制中,在本地存储的是经过加密的Key对象的JSON格式,所用的加密方法被称为Web3 Secret Storage,其实现细节可在ethereum git wiki上找到。下图是该存储方式的简单示意图:
对一个加密存储的Key对象做操作时,总共需要三个参数,包括调用方提供一个名为passphrase的任意字符串,以及keyStorePassphrase{}中给定的两个整型数scryptN,scryptP,这两个整型参数在keyStorePassphrase对象生命周期内部是固定不变的,只能在创建时赋值。这样不管是每次新存储一个Key对象,还是取出一个已存的Key对象,调用方都必须传入正确的参数passphrase,所以在实际应用中,以太坊钱包的客户必须自行记忆该字符串。实际上,客户为每个账户创建的密码password,程序中正是这个加密参数passphrase。
Key{}对象从加密过的本地文件中取出后,会被封装成unlocked{}对象,并被KeyStore放进其map[Address]*unlocked类型成员中。由于公钥密钥的重要性,显然keystore中存有的unlocked对象也应该控制公开时长。对于不同的时限需求,KeyStore{}提供了如下两个函数:
TimedUnlock()函数会在给定的时限到达后,立即将已知Account对应的unlocked对象中的PrivateKey的私钥销毁(逐个bit清0),并将该unlocked对象从KeyStore成员中删除。而Unlock()函数会将该unlocked对象一直公开,直到程序退出。注意,这里的清理工作仅仅是针对内存中的Key对象,而以加密方式存在本地的key文件不受影响。
keystore机制以本地文件的形式提供对账户信息和数字签名公钥私钥的存储和读取,从而以软件方式实现了accounts.的功能。它的两套独立的本地存储文件,既考虑了公钥私钥的加密又兼顾了账户信息的快速读取,体现出很全面的设计思路。
以太坊除了提供软件实现的钱包之外,还有硬件实现的钱包。当然,对于硬件钱包,以太坊代码中肯定有上层代码对此进行封装。这些代码都处于/accounts/usbwallet/下,它们的UML关系如下图所示:
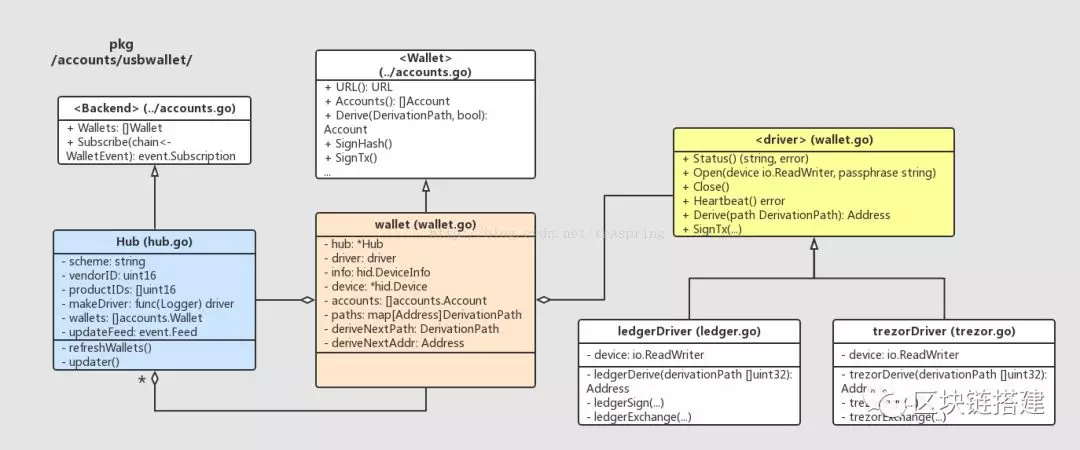
· 接口从命名就看得出来,它用来封装下层硬件实现钱包的代码。尽管严格来说,这个接口及其实现体跟一般意义上的驱动程序没什么关系。
·ledgerDriver{},trezorDriver{}分别对应于两家供应商发布的硬件数字货币钱包,Ledger 和 Trezor 分别是品牌名。它们都可以支持包括以太币在内的多种数字货币。
· 结构体,它实现了上层accounts.接口,地位相当于account.Manager。从代码来看,所有硬件实现的部分,都会由这个Hub对象来管理。Hub{}向外以接口的形式暴露,这样更上层的代码就不必区分下层钱包的具体实现是软件还是硬件了。
需要注意的是,在目前以太坊的主干代码中,硬件实现钱包有关数字签名部分,目前只能提供针对交易进行原生的数字签名功能,即仅仅.SignTx()函数可用,其他签名功能包括SignHash(),以及SignXXXWithPassphrase()均不支持,不知道其他分支代码是否有所不同。
在了解accounts代码包之后,我们就可以来看看以太坊源代码中最著名的类型,同时也是客户端程序中最核心的部分 -eth.Ethereum。能够以整个系统名命名的结构体类型,想必功能应该非常强大,下图是它的一个简单UML图:
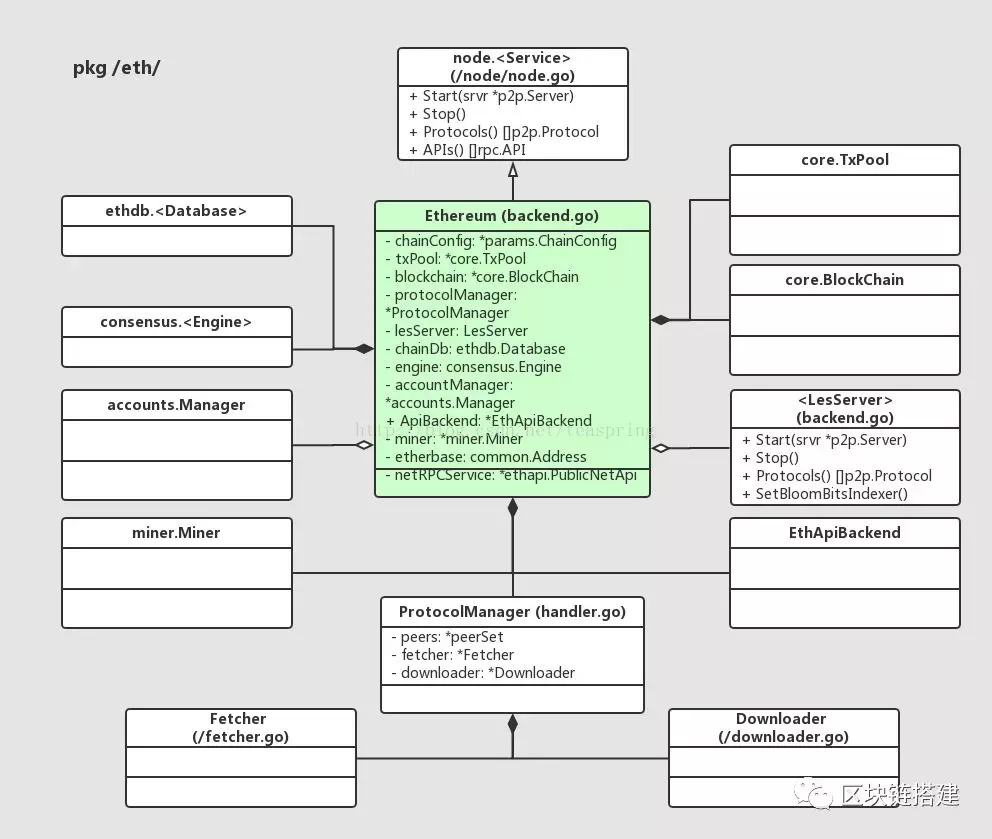
上图中央就是eth.Ethereum类型,四周都是它的成员变量类型,我们来看看其中哪些是已经了解过的:
· consensus. 是共识算法代码包向外暴露的函数接口,其实现包括基于PoW的Ethash算法,和基于PoA的Clique算法。
· accounts.Manager 是管理账户信息和数字签名公钥密钥信息的代码。
· miner.Miner 是挖掘新区块的代码,它可以管理挖掘新区块的整个流程,调用consensus.完成新区块的授勋/认证,并向外广播 新区块事件。
· core.TxPool 是积累新交易(Transaction, tx)对象的代码,每个新挖掘区块,都需要从TxPool中监听Tx更新事件并获取新交易集合以组装成新区块。
以上这些都是前文中都已经具体介绍过的代码部分,接着再来看看那些新的类型:
· node.,这是客户端程序用以对节点进行功能抽象的接口。每个客户端都把自身视为网络中的一个节点(node),这个节点向外所提供的所有功能,由接口来定义。
· :实现LES协议的函数接口,eth.其实是为了调用les.LesServer{}而专门创建的本地函数接口。
· EthApiBackend, 它是帮助Ethereum把各项功能以RPC 服务(service)的方式暴露出去的模块,外部调用方以API的方式调用这些功能/服务。
·ProtocolManager,用来管理p2p通信。以太坊内部把每个个体(peer)与其他个体群之间的通信协议称为一种基于p2p通信协议的新协议。考虑到eth.Ethereum提供功能的全面性,它也被称为全节点服务的通信协议。
· ProtocolManager的成员变量中,Fetcher用以接收其他个体发来的宣布挖掘出新区块的消息并决定向对方获取需要的部分,Downloader负责整个区块链结构的同步(下载)。
特别介绍下LES:Light Ethereum Subprotocol(LES)是为轻量级客户端专门设计的子协议。相比于eth.Ethereum提供全节点服务的客户端,那些轻量级客户端不参与挖掘新区块,在与其他节点的通信中仅仅下载每个区快的头部(Block.Header),对于区块链的其他部分仅仅按需对部分同步。eth.Ehereum同时也支持LES,这样一个提供全节点服务的客户端就可以与其他轻量级客户端以相同的协议通信了。
对数字货币稍有了解的人应该都清楚p2p通信协议对于此类“去中心化”系统的重大意义。的确,把p2p通信协议称为以太坊系统的基石之一都不为过,从代码角度考虑, ProtocolManager及其代码族 也属于eth代码包的一部分,不过由于这部分代码比较复杂,会在下一篇文章中专门介绍这些通信协议的实现细节。
在了解eth.Ethereum这个核心服务之后,客户端执行程序也就呼之欲出了。首先有一个node.Node{}作为承载类似eth,Ethereum这样服务模块的容器:
从命令行启动geth客户端的程序就是以上,创建一个node.Node对象,从配置中读出想要注册的服务名,然后一一创建相应的服务对象,Node去启动它们。
geth是go-ethereum自带的命令行客户端程序,目前市场上也存在许多种其他的以太坊客户端程序,有兴趣的读者可以去找来看看,有源代码就最好了可以比较一下。
以太坊的客户端程序,原本应该是刚接触以太坊的初学者最早遇到的部分之一。因为下载完整个源代码包之后,按照相应语言的提示进行编译,就会得到一个客户端的可执行程序。我最初首先看的客户端的代码,当追溯到eth.Ethereum{}结构体,看到那么多模块的成员变量时,就一下子明白了,整个以太坊系统运行起来的基础模块是哪些部分。
1. 以太坊中代码中,accounts.Manager是管理账户信息的模块。Manager可以管理多个的实现,每个实现拥有多个Account账户,每个Account对应一个Address地址,而以太币Ether存放于每个Address上。以太坊同时提供软件版和硬件版的实现。
2. 以太坊中,每个Address类型变量均来自于椭圆曲线数字签名算法(ECDSA)所用的公钥,因此钱包程序还必须提供管理数字签名公钥密钥的功能。软件版accounts.实现叫keystore,通过在本地文件系统中分别显式存储账户信息和加密存储公钥密钥的方式,提供以上功能。
3. 以太坊客户端程序之间,会通过accounts.Manager模块相互订阅Wallet更新事件,以保证每个客户端个体(peer),都能及时更新全网络中的完整Wallet列表。
4.客户端程序的核心是eth.Ethereum,它以RPC service的形式,向外提供内部各模块的功能,诸如挖掘区块, 数据库读写,p2p下载等。
基本环节-交易,区块、区块链的存储方式等,这篇打算介绍一下“挖矿“得到新区块的整个过程,以及不同共识算法的实现细节。
在Ethereum 代码中,名为miner的包(package)负责向外提供一个“挖矿”得到的新区块,其主要结构体的UML关系图如下图所示:
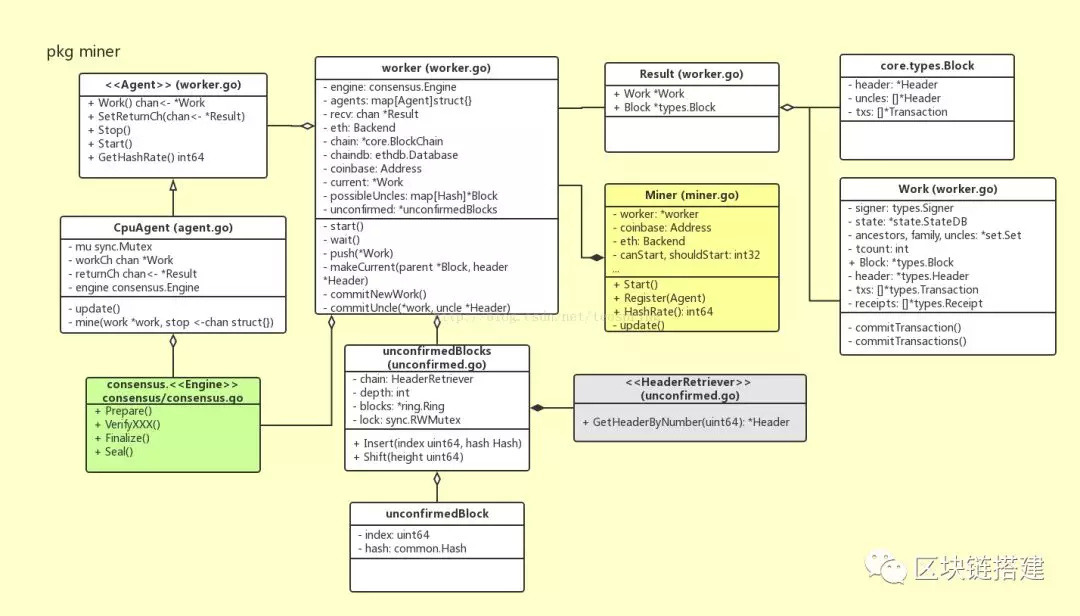
处于入口的类是Miner,它作为公共类型,向外暴露mine功能;它有一个worker类型的成员变量,负责管理mine过程;worker内部有一组Agent接口类型对象,每个Agent都可以完成单个区块的mine,目测这些Agent之间应该是竞争关系;Work结构体主要用以携带数据,被视为挖掘一个区块时所需的数据环境。
主要的数据传输发生在worker和它的Agent(们)之间:在合适的时候,worker把一个Work对象发送给每个Agent,然后任何一个Agent完成mine时,将一个经过授权确认的Block加上那个更新过的Work,组成一个Result对象发送回worker。
有意思的是Agent接口,尽管调用方worker内部声明了一个Agent数组,但目前只有一个实现类CpuAgent的对象会被加到该数组,可能这个Agent数组是为将来的扩展作的预留吧。CpuAgent通过全局的Engine对象,借助共识算法完成最终的区块授权。
另外,unconfirmedBlocks 也挺特别,它会以unconfirmedBlock的形式存储最近一些本地挖掘出的区块。在一段时间之后,根据区块的Number和Hash,再确定这些区块是否已经被收纳进主干链(canonical chain)里,以输出Log的方式来告知用户。
对于一个新区块被挖掘出的过程,代码实现上基本分为两个环节:一是组装出一个新区块,这个区块的数据基本完整,包括成员Header的部分属性,以及交易列表txs,和叔区块组uncles[],并且所有交易已经执行完毕,所有收据(Receipt)也已收集完毕,这部分主要由worker完成;二是填补该区块剩余的成员属性,比如Header.Difficulty等,并完成授权,这些工作是由Agent调用接口实现体,利用共识算法来完成的。
挖掘新区块的流程入口在Miner里,略显奇葩的是,具体入口在Miner结构体的创建函数(避免称之为‘构造函数’)里。
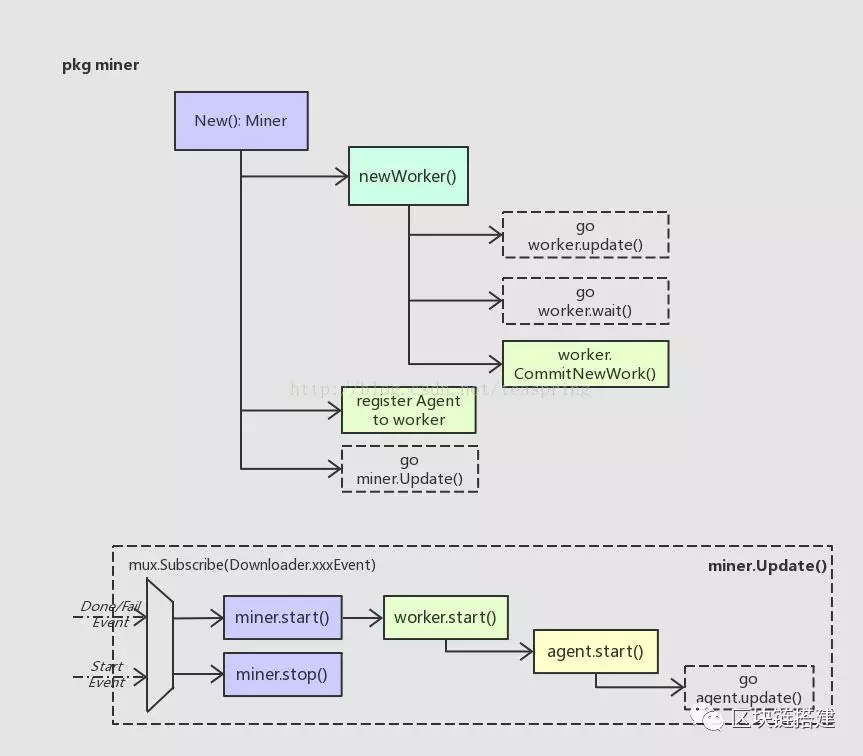
在New()里,针对新对象miner的各个成员变量初始化完成后,会紧跟着创建worker对象,然后将Agent对象登记给worker,最后用一个单独线程去运行miner.Update()函数;而worker的创建函数里也如法炮制,分别用单独线程去启动worker.updater()和wait();最后itNewWork()会开始准备一个新区块所需的基本数据,如Header,Txs, Uncles等。注意此时Agent尚未启动。
这个update()会订阅(监听)几种事件,均跟Downloader相关。当收到Downloader的StartEvent时,意味者此时本节点正在从其他节点下载新区块,这时miner会立即停止进行中的挖掘工作,并继续监听;如果收到DoneEvent或FailEvent时,意味本节点的下载任务已结束-无论下载成功或失败-此时都可以开始挖掘新区块,并且此时会退出Downloader事件的监听。
从miner.Update()的逻辑可以看出,对于任何一个Ethereum网络中的节点来说,挖掘一个新区块和从其他节点下载、同步一个新区块,根本是相互冲突的。这样的规定,保证了在某个节点上,一个新区块只可能有一种来源,这可以大大降低可能出现的区块冲突,并避免全网中计算资源的浪费。
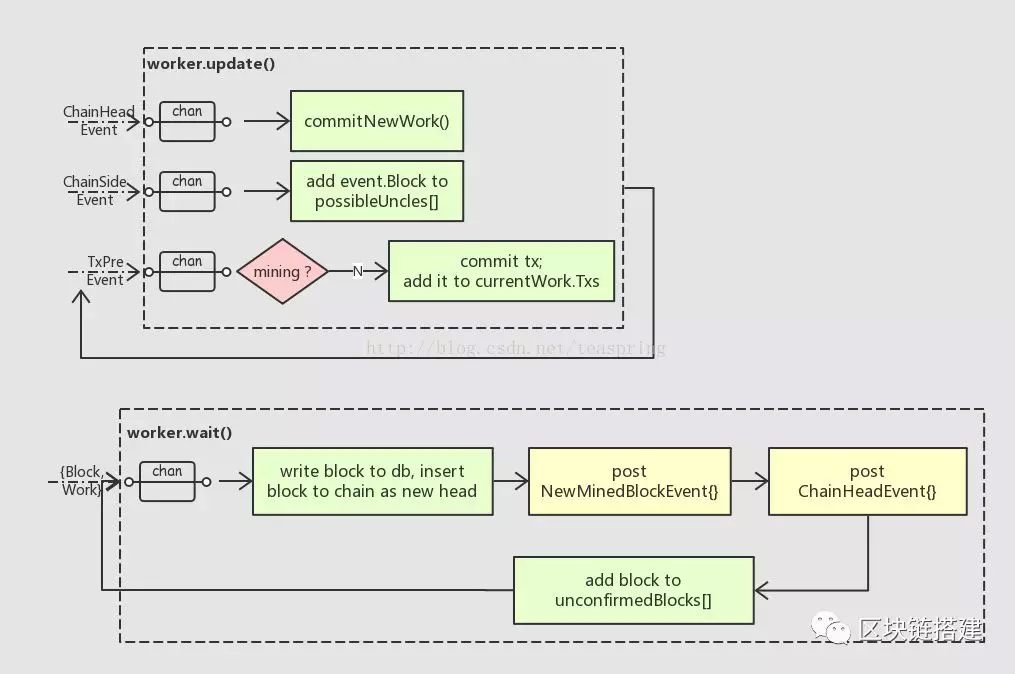
worker.update()分别监听ChainHeadEvent,ChainSideEvent,TxPreEvent几个事件,每个事件会触发worker不同的反应。ChainHeadEvent是指区块链中已经加入了一个新的区块作为整个链的链头,这时worker的回应是立即开始准备挖掘下一个新区块(也是够忙的);ChainSideEvent指区块链中加入了一个新区块作为当前链头的旁支,worker会把这个区块收纳进possibleUncles[]数组,作为下一个挖掘新区块可能的Uncle之一;TxPreEvent是TxPool对象发出的,指的是一个新的交易tx被加入了TxPool,这时如果worker没有处于挖掘中,那么就去执行这个tx,并把它收纳进Work.txs数组,为下次挖掘新区块备用。
需要稍稍注意的是,ChainHeadEvent并不一定是外部源发出。由于worker对象有个成员变量chain(eth.BlockChain),所以当worker自己完成挖掘一个新区块,并把它写入数据库,加进区块链里成为新的链头时,worker自己也可以调用chain发出一个ChainHeadEvent,从而被worker.update()函数监听到,进入下一次区块挖掘。
worker.wait()会在一个channel处一直等待Agent完成挖掘发送回来的新Block和Work对象。这个Block会被写入数据库,加入本地的区块链试图成为最新的链头。注意,此时区块中的所有交易,假设都已经被执行过了,所以这里的操作,不会再去执行这些交易对象。
当这一切都完成,worker就会发送一条事件(NewMinedBlockEvent{}),等于通告天下:我挖出了一个新区块!这样监听到该事件的其他节点,就会根据自身的状况,来决定是否接受这个新区块成为全网中公认的区块链新的链头。至于这个公认过程如何实现,就属于共识算法的范畴了。
commitNewWork()会在worker内部多处被调用,注意它每次都是被直接调用,并没有以goroutine的方式启动。commitNewWork()内部使用sync.Mutex对全部操作做了隔离。这个函数的基本逻辑如下:
1. 准备新区块的时间属性Header.Time,一般均等于系统当前时间,不过要确保父区块的时间(parentBlock.Time())要早于新区块的时间,父区块当然来自当前区块链的链头了。
4. 根据新区块的位置(Number),查看它是否处于DAO硬分叉的影响范围内,如果是,则赋值予header.Extra。
6. 如果配置信息中支持硬分叉,在Work对象的StateDB里应用硬分叉。
7. 准备新区块的交易列表,来源是TxPool中那些最近加入的tx,并执行这些交易。
10. 如果上一个区块(即旧的链头区块)处于unconfirmedBlocks中,意味着它也是由本节点挖掘出来的,尝试去验证它已经被吸纳进主干链中。
11. 把创建的Work对象,通过channel发送给每一个登记过的Agent,进行后续的挖掘。
以上步骤中,4和6都是仅仅在该区块配置中支持DAO硬分叉,并且该区块的位置正好处于DAO硬分叉影响范围内时才会发生;其他步骤是普遍性的。commitNewWork()完成了待挖掘区块的组装,block.Header创建完毕,交易数组txs,叔区块Uncles[]都已取得,并且由于所有交易被执行完毕,相应的Receipt[]也已获得。万事俱备,可以交给Agent进行‘挖掘’了。
显然,这两个函数都没做什么实质性工作,它们只是负责调用接口实现体,待授权完成后将区块数据发送回worker。挖掘出一个区块的真正奥妙全在Engine实现体所代表的共识算法里。
共识算法族对外暴露的是Engine接口,其有两种实现体,分别是基于运算能力的Ethash算法和基于“同行”认证的的Clique算法。
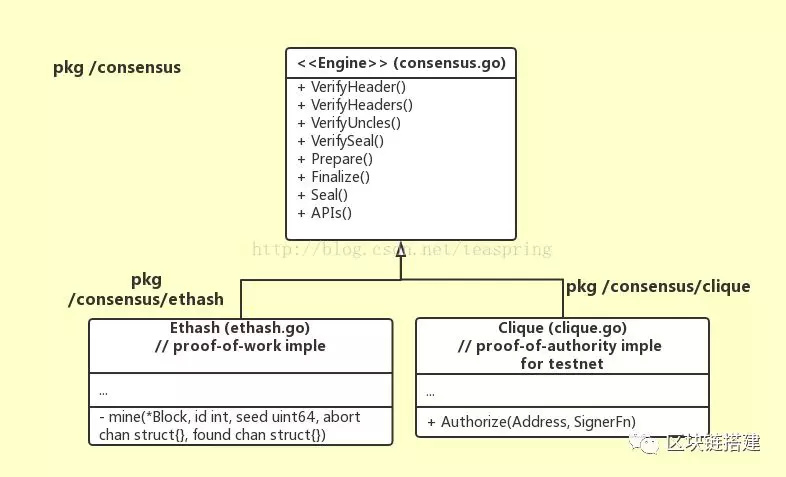
而Seal()和VerifySeal()是Engine接口所有函数中最重要的。Seal()函数可对一个调用过Finalize()的区块进行授权或封印,并将封印过程产生的一些值赋予区块中剩余尚未赋值的成员(Header.Nonce, Header.MixDigest)。Seal()成功时返回的区块全部成员齐整,可视为一个正常区块,可被广播到整个网络中,也可以入区块链等。所以,对于挖掘一个新区块来说,所有相关代码里Engine.Seal()是其中最重要,也是最复杂的一步。VerifySeal()函数基于跟Seal()完全一样的算法原理,通过验证区块的某些属性(Header.Nonce,Header.MixDigest等)是否正确,来确定该区块是否已经经过Seal操作。
在两种共识算法的实现中,Ethash是产品环境下以太坊真正使用的共识算法,Clique主要针对以太坊的测试网络运作,两种共识算法的差异,主要体现在Seal()的实现上。
Ethash算法又被称为Proof-of-Work(PoW),是基于运算能力的授权/封印过程。Ethash实现的Seal()函数,其基本原理可简单表示成以下公式:
这里M表示一个极大的数,比如2^256-1;d表示Header成员Difficulty。RAND()是一个概念函数,它代表了一系列复杂的运算,并最终产生一个类似随机的数。这个函数包括两个基本入参:h是Header的哈希值(Header.HashNoNonce()),n表示Header成员Nonce。整个关系式可以大致理解为,在最大不超过M的范围内,以某个方式试图找到一个数,如果这个数符合条件(=M/d),那么就认为Seal()成功。
我们可以先定性的验证一个推论:d的大小对整个关系式的影响。假设h,n均不变,如果d变大,则M/d变小,那么对于RAND()生成一个满足该条件的数值,显然其概率是下降的,即意味着难度将加大。考虑到以上变量的含义,当Header.Difficulty逐渐变大时,这个对应区块被挖掘出的难度(恰为Difficulty本义)也在缓慢增大,挖掘所需时间也在增长,所以上述推论是合理的。
以上代码就是mine()函数的主要业务逻辑。入参@id是线程编号,用来发送log告知上层;函数内部首先定义一组局部变量,包括之后调用hashimotoFull()时传入的hash、nonce、巨大的辅助数组dataset,以及结果比较的target;然后是一个无限循环,每次调用hashimotoFull()进行一系列复杂运算,一旦它的返回值符合条件,就复制Header对象(深度拷贝),并赋值Nonce、MixDigest属性,返回经过授权的区块。注意到在每次循环运算时,nonce还会自增+1,使得每次循环中的计算都各不相同。
这里的lookup()函数其实很重要,它其实是一个以非线性表查找方式进行的哈希函数! 这种哈希函数的性能不仅取决于查找的逻辑,更多的依赖于所查找的表格的数据规模大小。lookup()会以函数型参数的形式传递给hashimoto()
最终为Ethash共识算法的Seal过程执行运算任务的是hashimoto()函数,它的函数类型如下:
hashimoto()的逻辑比较复杂,包含了多次、多种哈希运算。下面尝试从其中数据结构变化的角度来简单描述之:
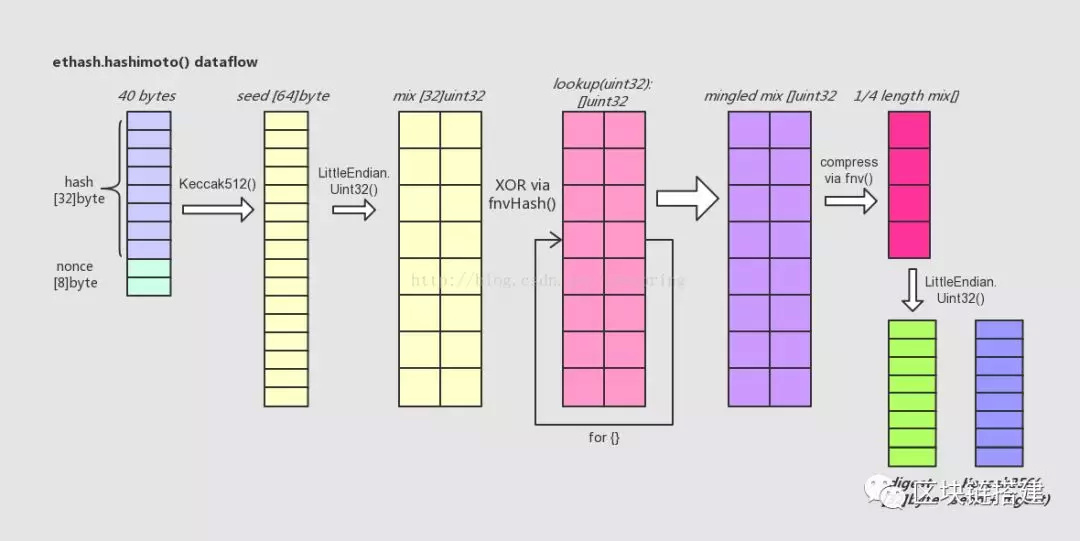
· 接着,lookup()函数登场。用一个循环,不断调用lookup()从外部数据集中取出uint32元素类型数组,向mix[]数组中混入未知的数据。循环的次数可用参数调节,目前设为64次。每次循环中,变化生成参数index,从而使得每次调用lookup()函数取出的数组都各不相同。这里混入数据的方式是一种类似向量“异或”的操作,来自于FNV算法。
· 待混淆数据完成后,得到一个基本上面目全非的mix[],长度为32的uint32数组。这时,将其折叠(压缩)成一个长度缩小成原长1/4的uint32数组,折叠的操作方法还是来自FNV算法。
· 最后,将折叠后的mix[]由长度为8的uint32型数组直接转化成一个长度32的byte数组,这就是返回值@digest;同时将之前的seed[]数组与digest合并再取一次SHA-256哈希值,得到的长度32的byte数组,即返回值@result。
上述hashimoto()函数中,函数型入参lookup()其实表示的是一次以非线性表查找方式进行的哈希运算,lookup()以入参为key,从所关联的数据集中按照定义好的一段逻辑取出64 bytes长的数据作为hash value并返回,注意返回值以uint32的形式则相应变成16个uint32长。返回的数据会在hashimoto()函数被其他的哈希运算所使用。
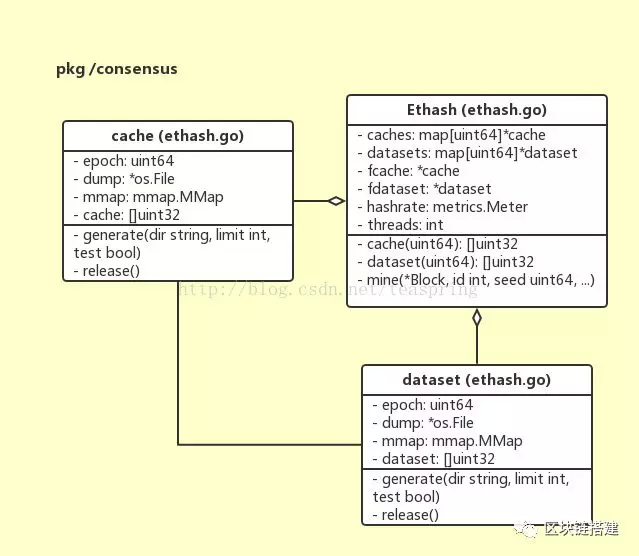
以cache{}的结构体声明为例,成员cache就是实际使用的一块内存Buffer,mmap是内存映射对象,dump是该内存buffer存储于磁盘空间的文件对象,epoch是共享这个cache{}对象的一组区块的序号。从上述UML图来看,cache和dataset的结构体声明基本一样,这也暗示了它们无论是原理还是行为都极为相似。
dataset{}和cache{}的生成过程很类似,都是通过内存映射的方式读/写磁盘文件。
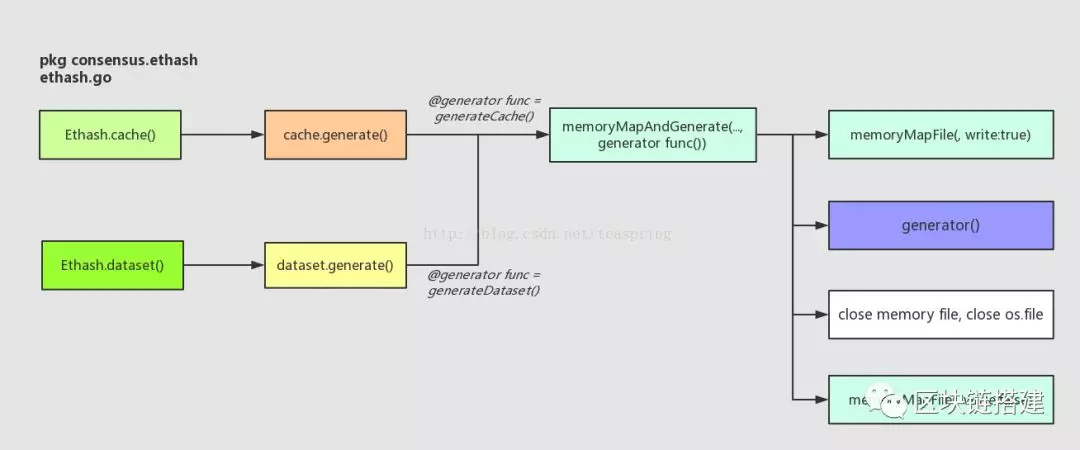
有意思的是内存映射相关的函数,memoryMapAndGenerate()会首先调用memoryMapFile()生成一个文件并映射到内存中的一个数组,并调用传入的函数型参数generator() 进行数据的填入,于是这个内存数组以及所映射的磁盘文件就同时变得十分巨大,注意此时传入memoryMapFile()的文件操作权限是可写的。然后再关闭所有文件操作符,调用memoryMapFile()重新打开这个磁盘文件并映射到内存的一个数组,注意此时的文件操作权限是只读的。可见这组函数的coding很精细。

上图是cache.generate()方法的基本流程:如果是测试用途,则不必考虑磁盘文件,直接调用generateCache()创建buffer;如果文件夹为空,那也没法拼接出文件路径,同样直接调用generateCache()创建buffer;然后根据拼接出的文件路径,先尝试读取磁盘上已有文件,如果成功,说明文件已存在并可使用;如果文件不存在,那只好创建一个新文件,定义文件容量,然后利用内存映射将其导入内存。很明显,直接为cache{]创建buffer的generateCache()函数是这里的核心操作,包括memoryMapAndGenerate()方法,都将generateCache()作为一个函数型参数引入操作的。
上述就是生成size的代码,cacheSize()的入参虽然是跟区块Number相关,但实际上对于处于同一epoch组的区块来说效果是一样的,每组个数epochLength。Ethash在代码里预先定义了一个数组cacheSizes[],存放了前2048个epoch组所用到的cache size。如果当前区块的epoch处于这个范围内,则取用之;若没有,则以下列公式赋初始值。
上述seedHash()函数用来生成所需的seed[]数组,它的长度32bytes,与common.Address类型长度相同。makeHasher()函数利用入参的哈希函数接口生成一个哈希函数,这里用了SHA3-256哈希函数。注意seedHash()中利用生成的哈希函数keccak256()对seed[]做的原地哈希,而原地哈希运算的次数跟当前区块所处的epoch序号有关,所以每个不同的cache{}所用到的seed[]也是完全不同的,这个不同通过更多次的哈希运算来实现。
由于Ethash(PoW)算法中用到的随机数据集cache{}和dataset{}过于庞大,将其以文件形式存储在磁盘上就显得很有必要。同样由于这些文件过于庞大,使用时又需要一次性整体读入内存(因为对其的使用是随意截取其中的一段数据),使用内存映射可以大大减轻I/O负担。cache{}和dataset{}结构体中,均有一个mmap对象用以操作内存映射,以及一个系统文件对象dump,对应于打开的磁盘文件。
回看一下Ethash共识算法最基本的形态,如果把整个result[]的生成过程视作那个概念上的函数RAND(),则如何能更加随机,分布更加均匀的生成数组,关系到整个Ethash算法的安全性。毕竟如果result[]生成过程存在被破译的途径,那么必然有方法可以更快地找到符合条件的数组,通过更快的挖掘出区块,在整个以太坊系统中逐渐占据主导。所以Ethash共识算法应用了非常复杂的一系列运算,包含了多次、多种不同的哈希函数运算:
1. 大量使用SHA3哈希函数,包括256-bit和512-bit形式的,用它们来对数据(组)作哈希运算,或者充当其他更复杂哈希计算的某个原型 -- 比如调用makeHasher()。而SHA3哈希函数,是一种典型的可应对长度变化的输入数据的哈希函数,输出结果长度统一(可指定256bits或512bits)。
2. lookup()函数提供了非线性表格查找方式的哈希函数,相关联的dataset{}和cache{}规模巨大,其中数据的生成/填充过程中也大量使用哈希函数。
3. 在一些计算过程中,有意将[]byte数组转化为uint32或uint64整型数进行操作(比如XOR,以及类XOR的FNV()函数)。因为理论证实,在32位或64位CPU机器上,以32位/64位整型数进行操作时,速度更快。
其中F()是数字签名函数,n是生成的数字签名,pr是公钥,h是被加密的内容。具体到Clique应用中,n是一个65 bytes长的字符串,pr是一个common.Address类型的(长度20 bytes)地址,h是一个common.Hash类型(32 bytes)的哈希值,而签名算法F(),目前采用的正是椭圆曲线数字签名算法(ECDSA)。
没错,就是这个被用来生成交易(Transaction)对象的数字签名的ECDSA。在Clique的实现中,这里用作公钥的Address类型地址有一个限制,它必须是已认证的(authorized)。所以Clique.Seal()函数的基本逻辑就是:有一个Address类型地址打算用作数字签名的公钥(不是区块的作者地址Coinbase);如果它是已认证的,则执行指定的数字签名算法。而其中涉及到的动态管理所有认证地址的机制,才是Clique算法(PoA)的精髓。
首先了解一下Clique的认证机制authorization所包括的一些设定:
1. 所有的地址(Address类型)分为两类,分别是经过认证的,和未经过认证的。
2. 已认证地址(authorized)可以变成未认证的,反之亦然。不过这些变化都必须通过投票机制完成。
3. 一张投票包括:投票方地址,被投票地址,和被投票地址的新认证状态。有效投票必须满足:被投票地址的新认证地址与其现状相反。
这些设定理解起来并不困难,把这里的地址替换成平常生活中的普通个体,这就是个很普通的投票制度。Clique算法中的投票系统的巧妙之处在于,每张投票并不是某个投票方主动“投”出来的,而是随机组合出来的。
想了解更多细节免不了要深入一些代码,下图是Clique算法中用到的一些结构体:

Clique结构体实现了共识算法接口Engine的所有方法,它可对区块作Seal操作。它的成员signFn正是数字签名生成函数,signer用作数字签名的公钥,这两成员均由Authorize()函数进行赋值。它还有一个map类型成员proposals,用来存放所有的不记名投票,即每张投票只带有被投票地址和投票内容(新认证状态),由于是map类型,显然这里的proposals存放的是内容不同的不记名投票。API结构体对外提供方法,可以向Clique的成员变量proposals插入或删除投票。
Snapshot结构体用来动态管理认证地址列表,在这里认证地址是分批次存储和更新的,一个Snapshot对象,存放的是以区块为时序的所有认证地址的快照。Snapshot的成员Number和Hash,正是区块Block的标志属性;成员Signers存储所有已认证地址。
一个Vote对象表示一张记名投票。Tally结构体用来记录投票数据,即某个(被投票)地址总共被投了多少票,新认证状态是什么。Snapshot中用map型变量Tally来管理所有Tally对象数据,map的key是被投票地址,所以Snapshot.Tally记录了被投票地址的投票次数。另外Snapshot还有一个Vote对象数组,记录所有投票数据。

上图解释了Clique.Prepare()方法中的部分逻辑。首先从proposals中筛选出有效的不记名投票,要么是已认证地址变为未认证,要么反过来;然后获取有效的被投票地址列表,从中随机选取一个地址作为该区块的Coinbase,与之相应的投票内容则被区块的Nonce属性携带。而新区块的Coinbase会在之后的更新认证地址环节,被当作一次投票的被投票地址。
ps,Ethash算法中,新区块的Coinbase地址可是异常重要的,因为它会作为新区块的作者地址,被系统奖励或补偿以太币。但Clique算法中就完全不同了,由于工作在测试网络中,每个帐号地址获得多少以太币没有实际意义,所以这里的Coinbase任意赋值倒也无妨。
管理所有认证地址的结构体是Snapshot,具体到更新认证地址列表的方法是apply()。它的基本流程如下图:
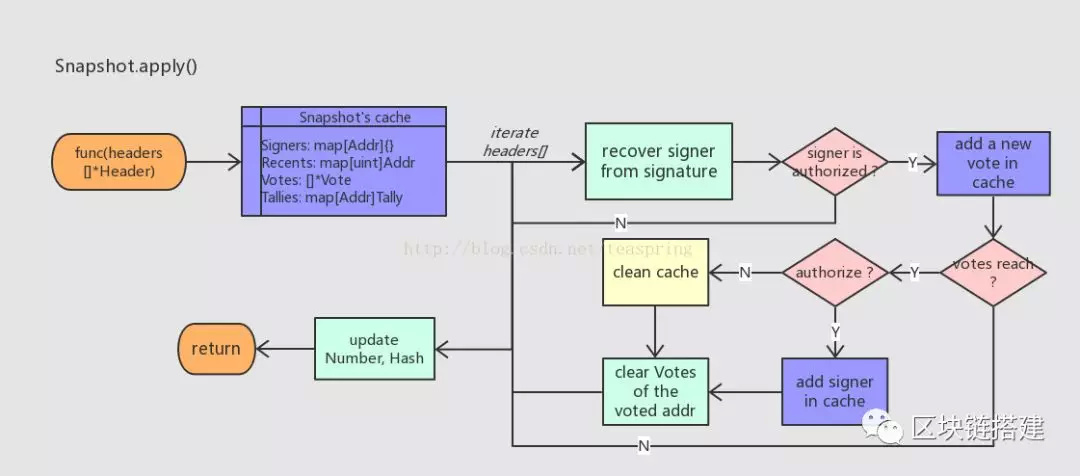
Signers是全部已认证地址集合,注意这里用map类型来提供Set的行为。
Recents用来记录最近担当过数字签名算法的signer的地址,通过它Snapshot可以控制某个地址不会频繁的担当signer。更重要的是,由于signer地址会充当记名投票的投票方,所以Recents可以避免某些地址频繁的充当投票方!Recents中map类型的key是区块Number值。
Votes记录了所有尚未失效的记名投票;Tallies记录了所有被投票地址(voted)目前的(被)投票次数。
Snapshot.apply()函数的入参是一组Header对象,它们来自区块主链上按从旧到新顺序排列的一组区块,并且严格衔接在Snapshot当前状态(成员Number,Hash)之后。注意,这些区块都是当前“待挖掘”新区块的祖先,所以它们的成员属性都是已经确定的。apply()方法的主要部分是迭代处理每个Header对象,处理单个Header的流程如下:
· 如果signer地址是尚未认证的,则直接退出本次迭代;如果是已认证的,则记名投票+1。所以一个父区块可添加一张记名投票,signer作为投票方地址,nbase作为被投票地址,投票内容authorized可由Header.Nonce取值确定。
· 更新投票统计信息。如果被投票地址的总投票次数达到已认证地址个数的一半,则通过之。
· 该被投票地址的认证状态立即被更改,根据是何种更改,相应的更新缓存数据,并删除过时的投票信息。
在所有Header对象都被处理完后,Snapshot内部的Number,Hash值会被更新,表明当前Snapshot快照结构已经更新到哪个区块了。
Snapshot.apply()方法在Clique.Seal()中被调用,具于运行数字签名算法之前,以保证即将充当公钥的地址可以用最新的认证地址列表加以验证。
2. 所有认证地址的动态更新,由一张张记名投票累计作用影响。而每张记名投票的投票方地址和投票内容(不记名投票),是以毫不相关、近乎随机的方式组合起来的。所以,理论上几乎不存在外部恶意调用代码从而操纵记名投票数据的可能。同时,通过一些内部缓存(Snapshot.Recents),避免了某些signer地址过于频繁的充当投票方地址。
虽然Clique共识算法并非作用在产品环境,但它依然很精巧的设计了完整的基于投票的选拔制度,很好的践行了去中心化宗旨。这对于其他类型共识算法的设计,提供了一个不错的样本。
那么这个具体怎么搭建怎么做呢怎么应用区块链的.去中心化.匿名公开.不可复制不可篡改可追溯技术呢大家有不懂的可以问我,不知道怎么搞区块链搭建交易所的也可以找我我们目前做区块链搭建主链侧链都做也有海内外货币牌照等等(国内大部分公司只会做侧链)工信部已经发布(中国区块链技术和应用发展白皮书) 360区块猫 百度莱茨狗 茅台 京东 万达 星巴克 腾讯多已经布局区块链, 既然这么多公司布局区块链来看,明眼人大致一看就知道区块链是未来的发展方向 我们目前能够做区块链主链开发 搭建货币电子钱包.区块链浏览器.交易平台系统.数字货币交易所.场内场外.上币落地app.项目白皮书.对接主流交易所.跨境支付.货币发行系统.主链开发.基金会发起.海内外货币牌照等一整套技术解决方案 (国内大部分只会做侧链)还有第一区块链认购溯源系统,可用在医疗 物流 食品肉类。第二养宠物系统 就像百度莱茨狗 小米加密兔 360区块猫 第三物联网和门禁系统可用在房产房租 第四金融行业方面跨境支付博彩银行等等都可以做,后续很有很多
小结本篇介绍了挖掘一个新区块在代码上的完整过程,从调用函数入口开始,沿调用过程一路向深,直至最终完成新区块授权/封印的共识算法,并对两种共识算法的设计思路和实现细节都进行了详细讲解。
· 一般所说的“挖掘一个新区块”其实包括两部分,第一阶段组装出新区块的所有数据成员,包括交易列表txs、叔区块uncles等,并且所有交易都已经执行完毕,各帐号状态更新完毕;第二阶段对该区块进行授勋/封印(Seal),没有成功Seal的区块不能被广播给其他节点。第二阶段所消耗的运算资源,远超第一阶段。
· Seal过程由共识算法(consensus algorithm)族完成,包括Ethash算法和Clique算法两种实现。前者是产品环境下真实采用的,后者是针对测试网络(testnet)使用的。Seal()函数并不会增加或修改区块中任何跟有效数据有关的部分,它的目的是通过一系列复杂的步骤,或计算或公认,选拔出能够出产新区块的个体。
· Ethash算法(PoW)基于运算能力来筛选出挖掘区块的获胜者,运算过程中使用了大量、多次、多种的哈希函数,通过极高的计算资源消耗,来限制某些节点通过超常规的计算能力轻易形成“中心化”倾向。
· Clique算法(PoA)利用数字签名算法完成Seal操作,不过签名所用公钥,同时也是common.Address类型的地址必须是已认证的。所有认证地址基于特殊的投票地址进行动态管理,记名投票由不记名投票和投票方地址随机组合而成,杜绝重复的不记名投票,严格限制外部代码恶意操纵投票数据
· 在实践“去中心化”方面,以太坊还在区块结构中增加了叔区块(uncles)成员以加大计算资源的消耗,并通过在交易执行环节对叔区块作者(挖掘者)的奖励,以收益机制来调动网络中各节点运算资源分布更加均匀.
闪电网络:数字货币的鼻祖的交易网络最为人诟病的一点便是交易性能:全网每秒 7 笔的交易速度,远低于传统的金融交易系统;同时,等待 6 个块的可信确认导致约 1 个小时的最终确认时间。闪电网络的主要思路十分简单 -- 将大量交易放到数字货币的鼻祖区块链之外进行。该设计最早是 2015 年 2 月在论文《The Bitcoin Lightning Network: Scalable Off-Chain Instant Payments》中提出。数字货币的鼻祖的区块链机制自身提供了很好的可信保障,但是很慢;另一方面考虑,对于大量的小额交易来说,是否真实需要这么高的可信性?闪电网络通过智能合约来完善链下的交易渠道。核心的概念主要有两个:RSMC(Recoverable Sequence Maturity Contract)和 HTLC(Hashed Timelock Contract)。前者解决了链下交易的确认问题,后者解决了支付通道的问题。闪电网络RSMC 保障了两个人之间的直接交易可以在链下完成,HTLC 保障了任意两个人之间的转账都可以通过一条“支付”通道来完成。整合这两种机制,就可以实现任意两个人之间的交易都可以在链下完成了。在整个交易中,智能合约起到了中介的重要角色,而区块链则确保最终的交易结果被确认。
RSMC:Recoverable Sequence Maturity Contract,中文可以翻译为“可撤销的顺序成熟度合同”。这个词很绕,其实主要原理很简单,就是类似准备金机制。我们先假定交易双方之间存在一个“微支付通道”(资金池)。双方都必须要放一些资金到“微支付通道”里,之后每次交易,就对交易后的资金分配方案共同进行确认,同时签字作废旧的版本。当需要提现时,将最终交易结果写到区块链网络中,被最终确认。可以看到,只有在提现时候才需要通过区块链。任何一个版本的方案都需要经过双方的签名认证才合法。任何一方在任何时候都可以提出提现,提现需要提供一个双方都签名过的资金分配方案(意味着肯定是某次交易后的结果)。在一定时间内,如果另外一方提出证明表明这个方案其实之前被作废了(非最新的交易结果),则资金罚没给质疑成功方。这就确保了没人会拿一个旧的交易结果来提现。另外,即使双方都确认了某次提现,首先提出提现一方的资金到账时间要晚于对方,这就鼓励大家尽量都在链外完成交易。
HTLC:微支付通道是通过 Hashed Timelock Contract 来实现的,中文意思是“哈希的带时钟的合约”。这个其实就是限时转账。理解起来其实也很简单,通过智能合约,双方约定转账方先冻结一笔钱,并提供一个哈希值,如果在一定时间内有人能提出一个字符串,使得它哈希后的值跟已知值匹配(实际上意味着转账方授权了接收方来提现),则这笔钱转给接收方。不太恰当的例子,约定一定时间内,有人知道了某个暗语(可以生成匹配的哈希值),就可以拿到这个指定的资金。推广一步,甲想转账给丙,丙先发给甲一个哈希值。甲可以先跟乙签订一个合同,如果你在一定时间内能告诉我一个暗语,我就给你多少钱。乙于是跑去跟丙签订一个合同,如果你告诉我那个暗语,我就给你多少钱。丙于是告诉乙暗语,拿到乙的钱,乙又从甲拿到钱。最终达到结果是甲转账给丙。这样甲和丙之间似乎构成了一条完整的虚拟的“支付通道”。
HTLC 的机制可以扩展到多个人,大家可以想象一下,想象出来了就理解了闪电网络。
共识机制:数字货币比特币的网络是公开的,因此共识协议的稳定性和防攻击性十分关键。数字货币的鼻祖的区块链技术采用了 Proof of Work(PoW)的机制来实现共识,该机制于 1998 年在 B-money 设计中提出。目前,Proof of 系列中比较出名的一致性协议包括 PoW 和 PoS,都是通过经济惩罚来限制恶意参与。
PoW:工作量证明,Proof of Work,通过计算来猜测一个数值(nonce),得以解决规定的 hash 问题(来源于 hashcash)。保证在一段时间内,系统中只能出现少数合法提案。同时,这些少量的合法提案会在网络中进行广播,收到的用户进行验证后会基于它认为的最长链上继续难题的计算。因此,系统中可能出现链的分叉(Fork),但最终会有一条链成为最长的链。hash 问题具有不可逆的特点,因此,目前除了暴力计算外,还没有有效的算法进行解决。反之,如果获得符合要求的 nonce,则说明在概率上是付出了对应的算力。谁的算力多,谁最先解决问题的概率就越大。当掌握超过全网一半算力时,从概率上就能控制网络中链的走向。这也是所谓 51% 攻击 的由来。参与 PoW 计算比赛的人,将付出不小的经济成本(硬件、电力、维护等)。当没有成为首个算出的“幸运儿”时,这些成本都将被沉没掉。这也保障了,如果有人恶意破坏,需要付出大量的经济成本。也有设计试图将后算出结果者的算力按照一定比例折合进下一轮比赛考虑。
有一个很直观的例子可以说明为何这种经济博弈模式会确保系统中最长链的唯一。
超市付款需要排成一队,可能有人不守规矩要插队。超市管理员会检查队伍,认为最长的一条队伍是合法的,并让不合法的分叉队伍重新排队。只要大部分人不傻,就会自觉在最长的队伍上排队。
权益证明,Proof of Stake,2013 年被提出,最早在 Peercoin 系统中被实现,类似现实生活中的股东机制,拥有股份越多的人越容易获取记账权。
典型的过程是通过保证金(代币、资产、名声等具备价值属性的物品即可)来对赌一个合法的块成为新的区块,收益为抵押资本的利息和交易服务费。提供证明的保证金(例如通过转账货币记录)越多,则获得记账权的概率就越大。合法记账者可以获得收益。
PoS 是试图解决在 PoW 中大量资源被浪费的缺点。恶意参与者将存在保证金被罚没的风险,即损失经济利益。
的资源,才有可能左右最终的结果。这个也很容易理解,三个人投票,前两人分别支持一方,这时候,第三方的投票将决定最终结果。PoS 也有一些改进的算法,包括授权股权证明机制(DPOS),即股东们投票选出一个董事会,董事会中成员才有权进行代理记账。
在非对称加密中,公钥则可以通过证书机制来进行保护,如何管理和分发证书则可以通过 PKI(Public Key Infrastructure)来保障。
顾名思义,PKI 体系在现代密码学应用领域处于十分基础的地位,解决了十分核心的证书管理问题。
PKI 并不代表某个特定的密码学技术和流程,PKI 是建立在公私钥基础上实现安全可靠传递消息和身份确认的一个通用框架。实现了 PKI 的平台可以安全可靠地管理网络中用户的密钥和证书,包括多个实现和变种,知名的有 RSA 公司的 PKCS(Public Key Cryptography Standards)标准和 X.509 规范等。
· CA(Certification Authority):负责证书的颁发和作废,接收来自 RA 的请求,是最核心的部分;
· RA(Registration Authority):对用户身份进行验证,校验数据合法性,负责登记,审核过了就发给 CA;
· 证书数据库:存放证书,一般采用 LDAP 目录服务,标准格式采用 X.500 系列。
常见的流程为,用户通过 RA 登记申请证书,CA 完成证书的制造,颁发给用户。用户需要撤销证书则向 CA 发出申请。
之前章节内容介绍过,密钥有两种类型:用于签名和用于加解密,对应称为签名密钥对 和 加密密钥对。
用户证书可以有两种方式。一般可以由 CA 来生成证书和私钥;也可以自己生成公钥和私钥,然后由 CA 来对公钥进行签发。后者情况下,当用户私钥丢失后,CA 无法完成恢复。我今天就先说到这里,我后面会接着分享,以前的文章大家可以自行翻看
